答题卡填涂识别
答题卡填涂识别
1 开发目的
我们在日常考试中不可避免的会使用到答题卡,而识别和批改答题卡却只能使用固定的读卡器。如果人一多效率低也不方便。所以我们能否利用 Python, 做一个好用的答题卡识别工具出来呢?
2 项目解释
2.1 使用技术
由于答题卡识别本质上还是 2D 图像识别,对于这一类型的需求。我们一般采用 opencv 完成。opencv 是一个极为强大的图片处理库,能够对图片完成复杂的处理
此外针对面向的群体,我制作了一个精美的 可视化界面 来帮助教师使用它。针对部署环境和封装后程序大小的考虑, 我采用了最基础的 tkinter 进行可视化界面的开发。作为 python 的自带库, 它的兼容性相当强。可以说只要你的电脑可以运行 Python 就可以用 tkinter,也规避了 Python 版本不同造成的语法不通的问题(tkinter 已经相当长时间没有更新了, Python 3.0 以后的 tkinter 语法没有较大差异)。并且由于 Python 自带 tkinter, 相应的环境部署也会较为简单
但 tkinter 也有着界面丑陋等等问题,虽然 tkinter 推出了 ttk 附属模块以支持使用当前系统风格的界面, 但这并不够。因此我引入了 sv_ttk 渲染引擎并对其进行修改,让 tkinter 不管在任何平台上都具有 WinUI 3.0 的风格界面
2.2 图像识别
2.2.1 简单处理
首先,我们先来观察一下答题卡是什么样子的
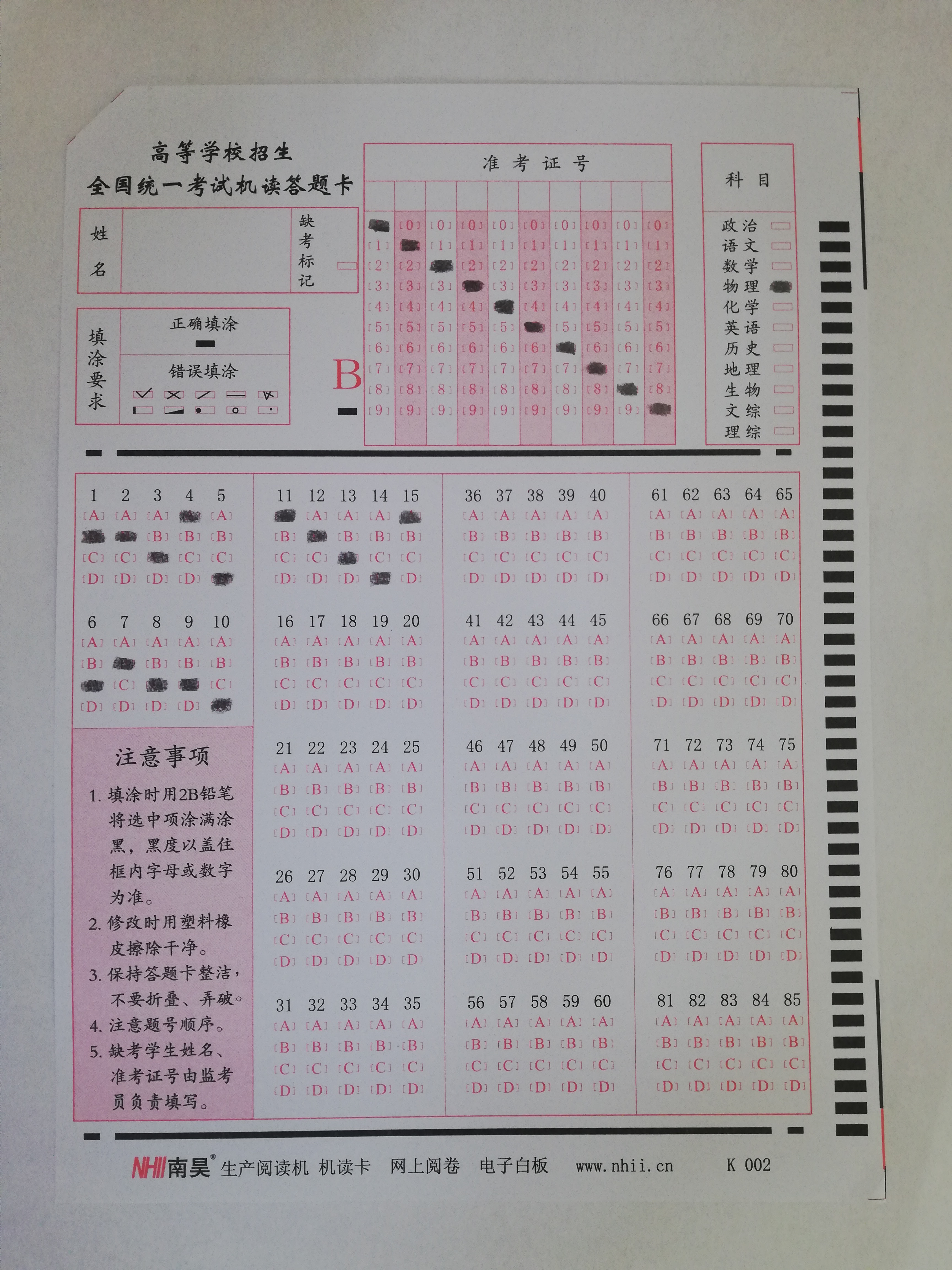
可以发现,铅笔的黑与答题卡的白形成了强烈的对比,我们可以将其转化为灰度图
# 将图像转换为灰度图像
def convert_to_gray(img):
return cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
之后应用高斯模糊,减少图片噪声
# 对图像应用高斯模糊,以减少图像噪声
def apply_gaussian_blur(img):
return cv2.GaussianBlur(img, (7, 7), 0)
再将其转化为二值图像
def apply_threshold(img):
return cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 15, 2)
在经过上一步之后,我们已经完成了图像的初步处理,现在我们要进行对图像进行拆分以方便后续的图像识别
首先我们要获取该图片存在的所有轮廓
# 使用 Canny 算法检测图像的边缘
def detect_edges(img):
return cv2.Canny(img, 10, 100)
# 找到图像中的轮廓
def find_contours(img):
cnts = cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
return cnts[1] if imutils.is_cv3() else cnts[0]
# 在所有轮廓中找到最大的矩形轮廓
def find_largest_rectangle(cnts):
if len(cnts) > 0:
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
for c in cnts:
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
if len(approx) == 4:
return approx
return None
之后将这些步骤执行一遍,在轮廓图中获取所有轮廓并用极点表示
# 主函数,用于获取四点转换的坐标
def getFourPtTrans(img):
gray = convert_to_gray(img) # 将图像转换为灰度图像
blurred = apply_gaussian_blur(gray) # 对灰度图像应用高斯模糊
thresholded = apply_threshold(blurred) # 对模糊的灰度图像应用阈值化
edged = detect_edges(thresholded) # 对阈值化的图像进行边缘检测
cnts = find_contours(edged) # 找到边缘检测图像的轮廓
docCnt = find_largest_rectangle(cnts) # 找到最大的矩形轮廓
if docCnt is not None:
docCnt = docCnt.reshape(4, 2) # 如果找到了矩形轮廓,将其重塑为 4x2 的矩阵
return docCnt # 返回矩形轮廓的坐标
提示
当时主要是考虑到可读性将步骤进行了拆分,也是为了我在以后的项目开发过程中能够便捷的对这些步骤复用
2.2.2 图像识别
我做了几个函数,他们都分别是一个步骤。这有助于代码的可读性
def getXY(docCnt):
'''传入四点坐标,返回(minX,minY,maxX,maxY)'''
# 初始化最小和最大的x、y坐标
minX, minY = docCnt[0]
maxX, maxY = docCnt[0]
# 遍历四点坐标,更新最小和最大的x、y坐标
for i in range(1, 4):
minX = min(minX, docCnt[i][0])
maxX = max(maxX, docCnt[i][0])
minY = min(minY, docCnt[i][1])
maxY = max(maxY, docCnt[i][1])
# 返回最小和最大的x、y坐标
return minX, minY, maxX, maxY
我们先找到最大和最小的 (x, y) 坐标,这样就能表示出一块区域
def judgeQ(x, y):
'''传入题号的x、y坐标,返回题号'''
# 根据x、y坐标计算题号
if x < 6:
return x + (y - 1) // 4 * 5
else:
return ((x - 1) // 5 - 1) * 25 + 10 + (x - 1) % 5 + 1 + (y - 1) // 4 * 5
之后通过题目的 (x, y) 坐标来计算题号,并返回它(这样才能批改)
def judgeAns(y):
'''传入答案的y坐标,返回答案'''
# 根据y坐标计算答案
if y % 4 == 1:
return 'A'
if y % 4 == 2:
return 'B'
if y % 4 == 3:
return 'C'
if y % 4 == 0:
return 'D'
细化到考生选了哪个选项,并将答案暂存。在后续会将其与正确答案对比来判断对错
因为答案是竖着排列的,同时只有四个选项且间隔相同,所以选项的 y 坐标一定与 4 有着一定的数学关系。通过简单分析可知,当取余后为 1 的则是 A, 而 D 作为第四个选项,恰好能除尽 4。以此类推
def judge0(x, y):
'''传入题号和答案的x、y坐标,返回(题号,答案)'''
# 返回题号和答案
return (judgeQ(x, y), judgeAns(y))
将上述函数整合,我们就能得到 题号 和题号对应的 考生答案
# 对原图像和灰度图像进行四点透视变换
paper = four_point_transform(img, docCnt)
warped = four_point_transform(gray, docCnt)
# 对灰度图像进行自适应阈值二值化
thresh = cv2.adaptiveThreshold(warped, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 15, 2)
# 将二值化图像、原图像和灰度图像调整为指定的宽度和高度
thresh, paper, warped = map(lambda img: cv2.resize(img, (width, height), cv2.INTER_LANCZOS4), [thresh, paper, warped])
# 对二值化图像进行模糊处理并进行阈值二值化
ChQImg = cv2.threshold(cv2.blur(thresh, (13, 13)), 120, 225, cv2.THRESH_BINARY)[1]
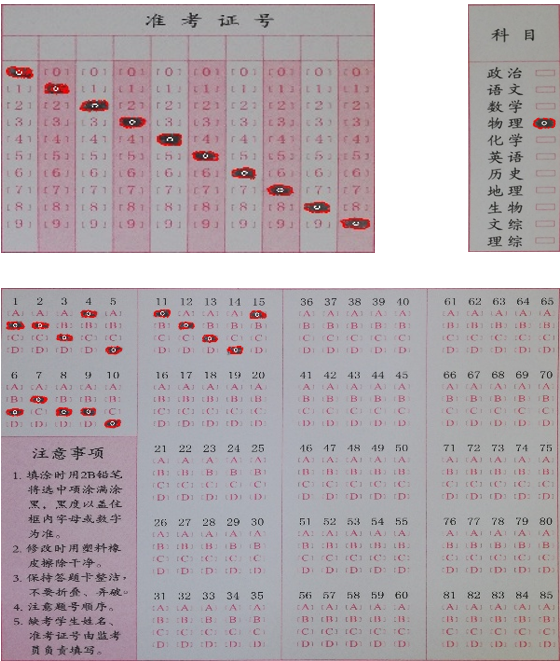
手机拍摄的图片会有一些角度的偏转,可以找到四个矩形的极点后,基于这四个极点对整张图片进行四点透视变换,把图片调整正,以方便进一步的使用
# 在二值化图像中找到轮廓
cnts = cv2.findContours(ChQImg, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[1] if imutils.is_cv3() else cnts[0]
# 遍历每一个轮廓
for c in cnts:
# 获取轮廓的边界框
x, y, w, h = cv2.boundingRect(c)
# 如果边界框的宽度和高度在指定范围内
if 50 < w < 100 and 20 < h < 100:
# 计算轮廓的质心
M = cv2.moments(c)
cX = int(M["m10"] / M["m00"])
cY = int(M["m01"] / M["m00"])
# 在原图像上画出轮廓和质心
cv2.drawContours(paper, c, -1, (0, 0, 255), 5)
cv2.circle(paper, (cX, cY), 7, (255, 255, 255), 2)
# 将质心坐标添加到答案列表中
Answer.append((cX, cY))
对于二值化后的图找轮廓,然后对轮廓进行矩形拟合,如果找到了跟选项框大小相近的轮廓,就认为是涂黑的选项,然后对这个轮廓求矩值,由这个公式可求出轮廓的重心
提示
公式来源于网络 OpenCV-Python教程:19.轮廓属性
2.2.3 处理数据
# 这里能识别到的最大方框是答题部分的方框,然后根据这个方框就可以推断出其他方框的大致位置
image=cv2.imread(imgPath)
# 搞到答案的四点坐标
ansCnt=getFourPtTrans(image)
xy=getXY(ansCnt)
xy=getXY(ansCnt)
# 切取上半部分的图
stuNum=image[0:xy[1],xy[0]:xy[2]]
numCnt=getFourPtTrans(stuNum)
xy=getXY(numCnt)
# 切右半部分的图,方便识别科目
course=image[0:int(xy[3]*1.1),xy[2]:len(image)]
利用四点坐标将图片进行裁切, 以方便获得对应的信息
'''处理答案'''
width1,height1=2300,1500
ansImg,Answer=markOnImg(image,width1,height1)
# 题号,答题卡上的答案
IDAnswer=[]
for a in Answer:
for x in range(0,len(xt1)-1):
if a[0]>xt1[x] and a[0]<xt1[x+1]:
for y in range(0,len(yt1)-1):
if a[1]>yt1[y] and a[1]<yt1[y+1]:
IDAnswer.append(judge0(x+1,y+1))
IDAnswer.sort()
ansImg=cv2.resize(ansImg,(600,400))
标记图像,并获得答案
'''处理学号'''
width2,height2=1000,1000
numImg,Answer=markOnImg(stuNum,width2,height2)
Answer.sort()
yt2=[227,311,374,442,509,577,644,711,781,844]
NO=''
for a in Answer:
for y in range(len(yt2)-1):
if a[1]>yt2[y] and a[1]<yt2[y+1]:
NO+=str(y)
if NO=='':
NO="Nan"
numImg=cv2.resize(numImg,(300,200))
'''处理科目'''
width3,height3=300,1000
courseImg,Answer=markOnImg(course,width3,height3)
yt3=list(range(250,1000,65))
s=-1
if len(Answer)>0:
for y in range(len(yt3)-1):
if Answer[0][1]>yt3[y] and Answer[0][1]<yt3[y+1]:
s=y
courseImg=cv2.resize(courseImg,(150,400))
course_checked="Nan"
if s!=-1:
course_checked=course_list[s]
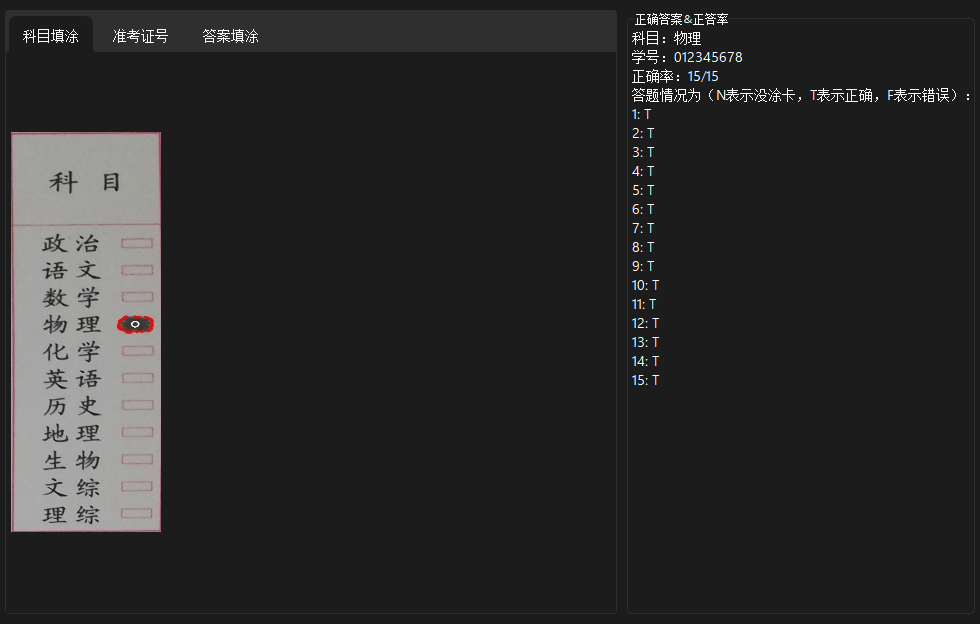
return ((numImg,courseImg,ansImg),(NO,course_checked,IDAnswer))
对答题卡进行透视变换后,每个位置对应的选项和题号都是固定的,通过人为的测量一些位置并记录,即可确定每个坐标对应的选项与题号
3 部署项目
3.1 准备环境
您的 Windows 版本不应低于 Windows 10,否则我无法保证其运行不会报错(未在 Windows 7 及更低的系统测试)
首先您需要安装以下第三方库
pip install scipy -i https://pypi.tuna.tsinghua.edu.cn/simple --user
pip install imutils -i https://pypi.tuna.tsinghua.edu.cn/simple --user
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple --user
pip install sv_ttk -i https://pypi.tuna.tsinghua.edu.cn/simple --user
之后请您运行以下代码或直接从 menu.pyw 中启动
python menu.pyw
您可以在 test 文件夹下拿到测试材料
3.2 如何使用
请你在项目文件中找到 Dist 文件夹
之后双击该应用程序 menu.exe
运行后会出现这样一个界面
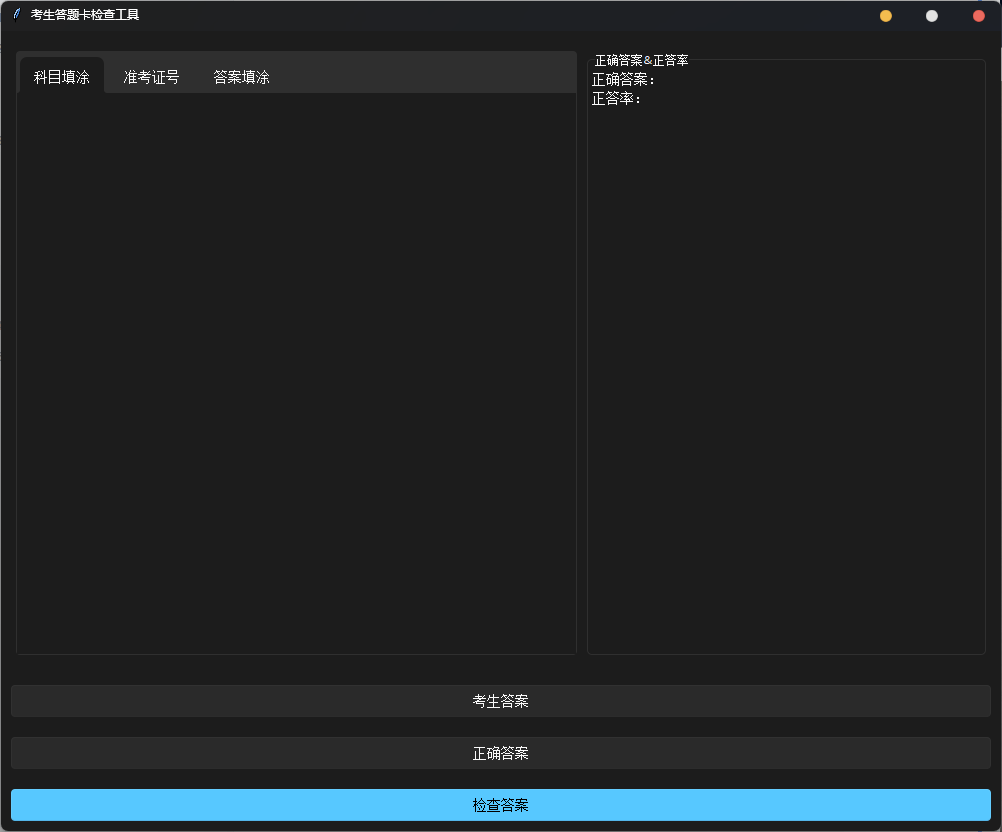
请点击 考生答案 并上传答题卡,如果您没有相应素材请在 test 文件夹中取用
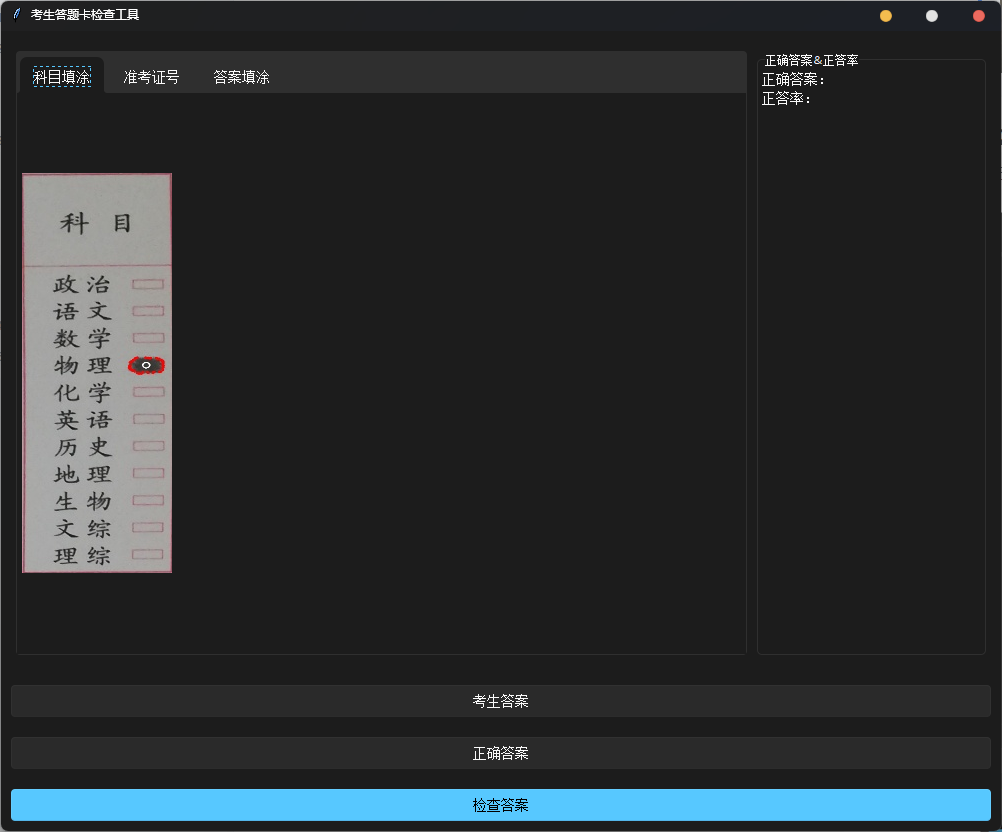
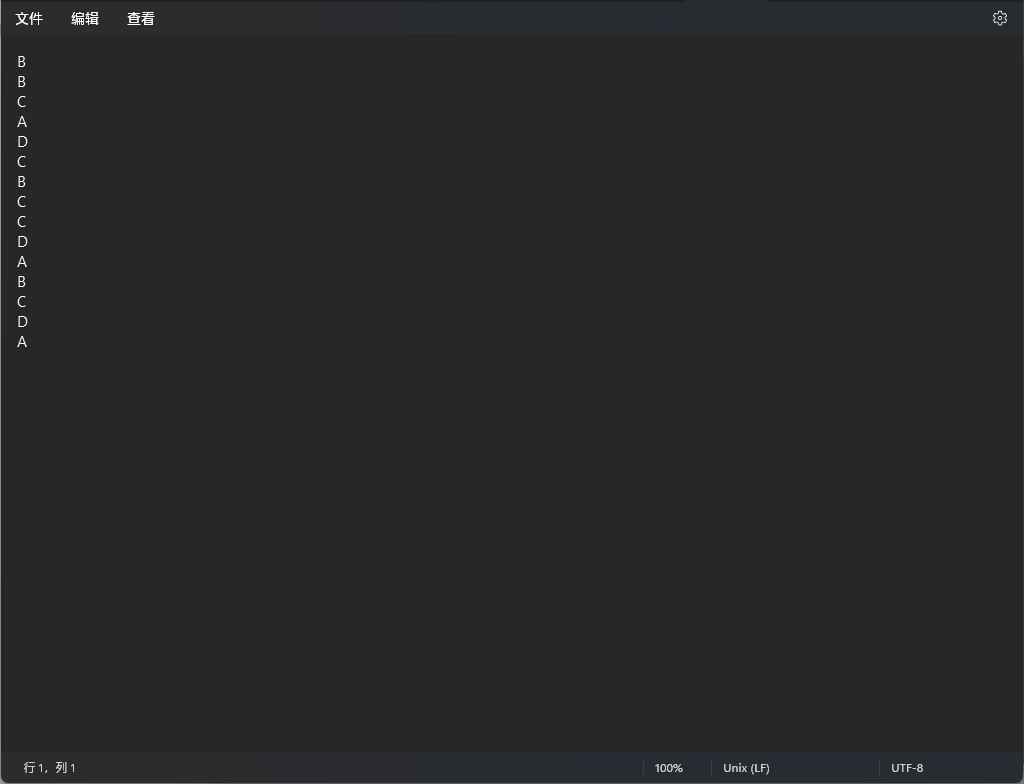
之后上传正确答案,在 test\case1 中,有一个 ans1.txt,那个就是提前写好的答案
注意
禁止使用中文路径存储!测试图片不能在中文路径下!否则会无法打开!!!
你也可以按照这样的格式自定义答案,每一个答案后换一行
之后点击 检查答案 即可